June 24th, 2026
New
Improved
Fixed

More accurate transcripts, starting today
We've overhauled how transcription works under the hood — and the result is a meaningful jump in accuracy for everyone, with no change to how you work.
Tested against the competition
We didn't just test on clean studio audio. We benchmarked our new defaults against leading models and competing services across 16 test suites — from clean baselines (LibriSpeech) to the hard, messy stuff that reflects real recordings: distant-mic meetings with overlapping speakers (AMI), real earnings calls with heavy jargon (Earnings-22), podcasts (Rev16), and diverse real-world media (Kincaid46, People's Speech). We also tested across four languages beyond English.
The takeaway: on par or better than every model and competitor we tested — and the gap is widest exactly where it's hardest, on noisy, real-world audio. Same speed you expect, noticeably better output.
Choose the balance that fits the job
You can now pick a transcription mode for the trade-off you care about — from Standard (our most accurate, and the new recommended default) to Balanced and Fast when you need speed.
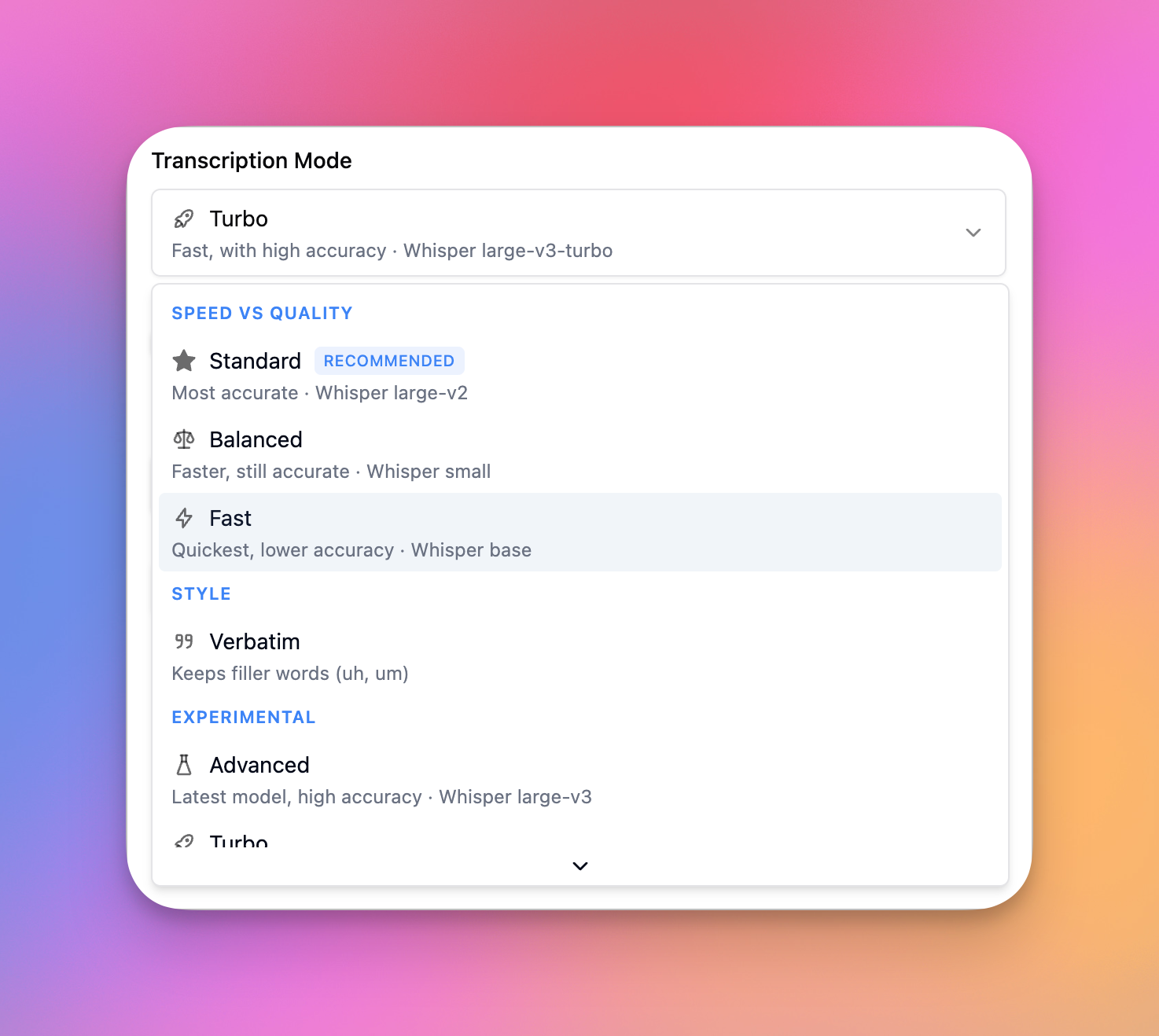
There's a Verbatim style that keeps filler words, plus experimental modes for those who want to test the latest.
What's next
This work isn't just about today's numbers — it lays the groundwork for domain-specific models. Specialised fields like medicine come with terminology that trips up general-purpose models, and we're now positioned to ship models tuned for exactly that. More on this soon.
As always, nothing to configure.
Just start transcribing,
Praveen